Introduction
What is Orbit.js?
Orbit is a framework for orchestrating access, transformation, and synchronization between data sources.
Orbit is written in Typescript and distributed on npm as packages containing a variety of module formats and ES language levels. Most Orbit packages are isomorphic—they can run in modern browsers as well as in the Node.js runtime.
Quick links
Looking a quick code walkthrough? Check out the Getting Started Guide.
Upgrading from v0.15? Learn what's new.
Orbit's goals
Orbit was primarily designed to support the data needs of ambitious client-side web applications, including:
Optimistic and pessimistic UX patterns.
Pluggable sources that share common interfaces, to allow similar behavior on different devices.
Connection durability by queueing and retrying requests.
Application durability by persisting all transient state.
Warm caches of data available immediately on startup.
Client-first / serverless development.
Custom request coordination across multiple sources, allowing for priority and fallback plans.
Branching and merging of data caches.
Deterministic change tracking.
Undo / redo editing support.
Basic constraints
In order to meet these ambitious goals, Orbit embraces a set of basic constraints related to data sources and interactions between them.
Disparate sources
Any number of data sources of varying types and faculties may be required to build any given web application.
Disparate data

Sources of data vary widely in how they internally represent and access that data.
Compatible interfaces
Communication between sources must happen using a compatible set of interfaces.
Normalized data
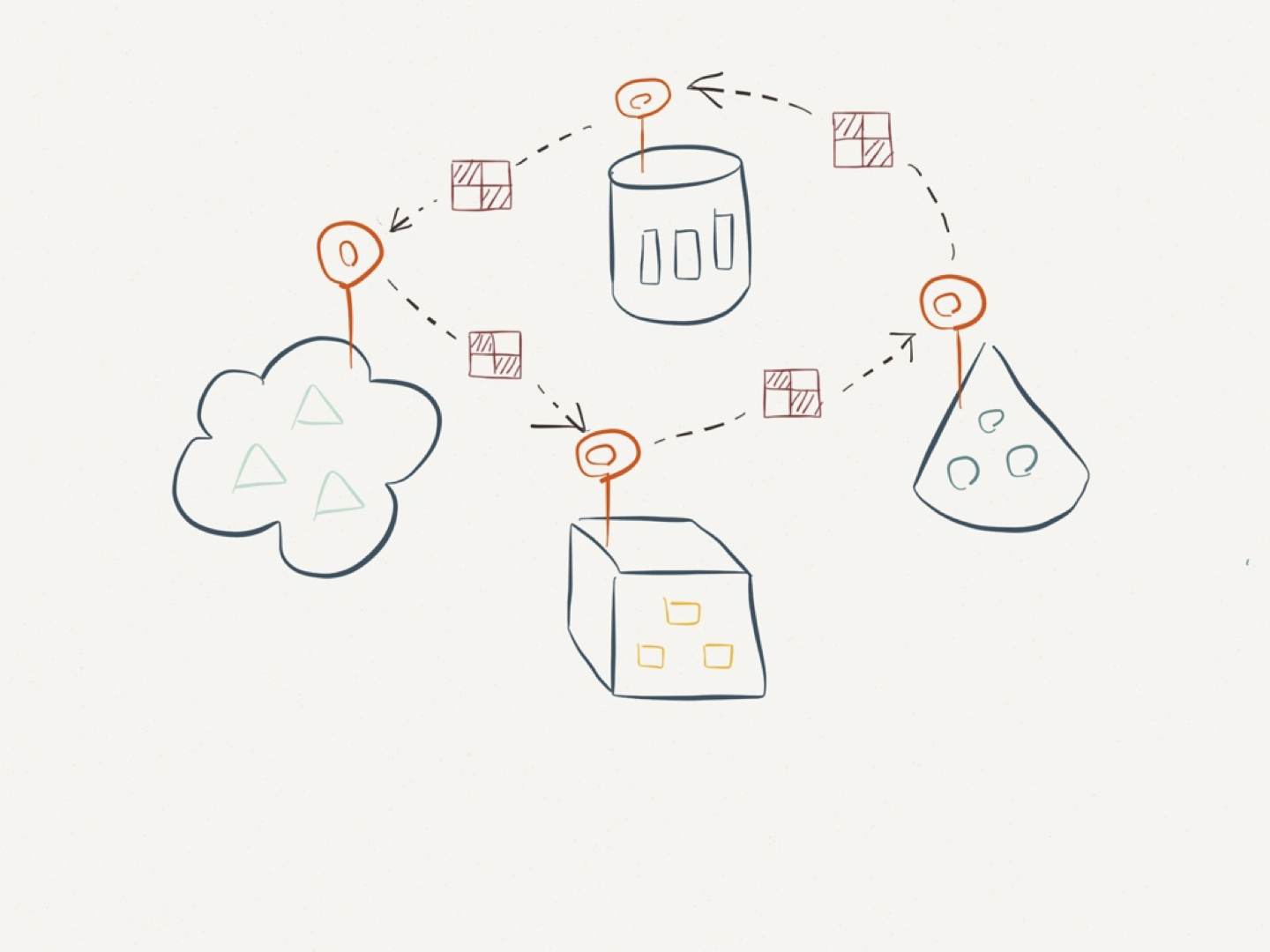
Data that flows between sources must be normalized to a shared schema.
Notifications
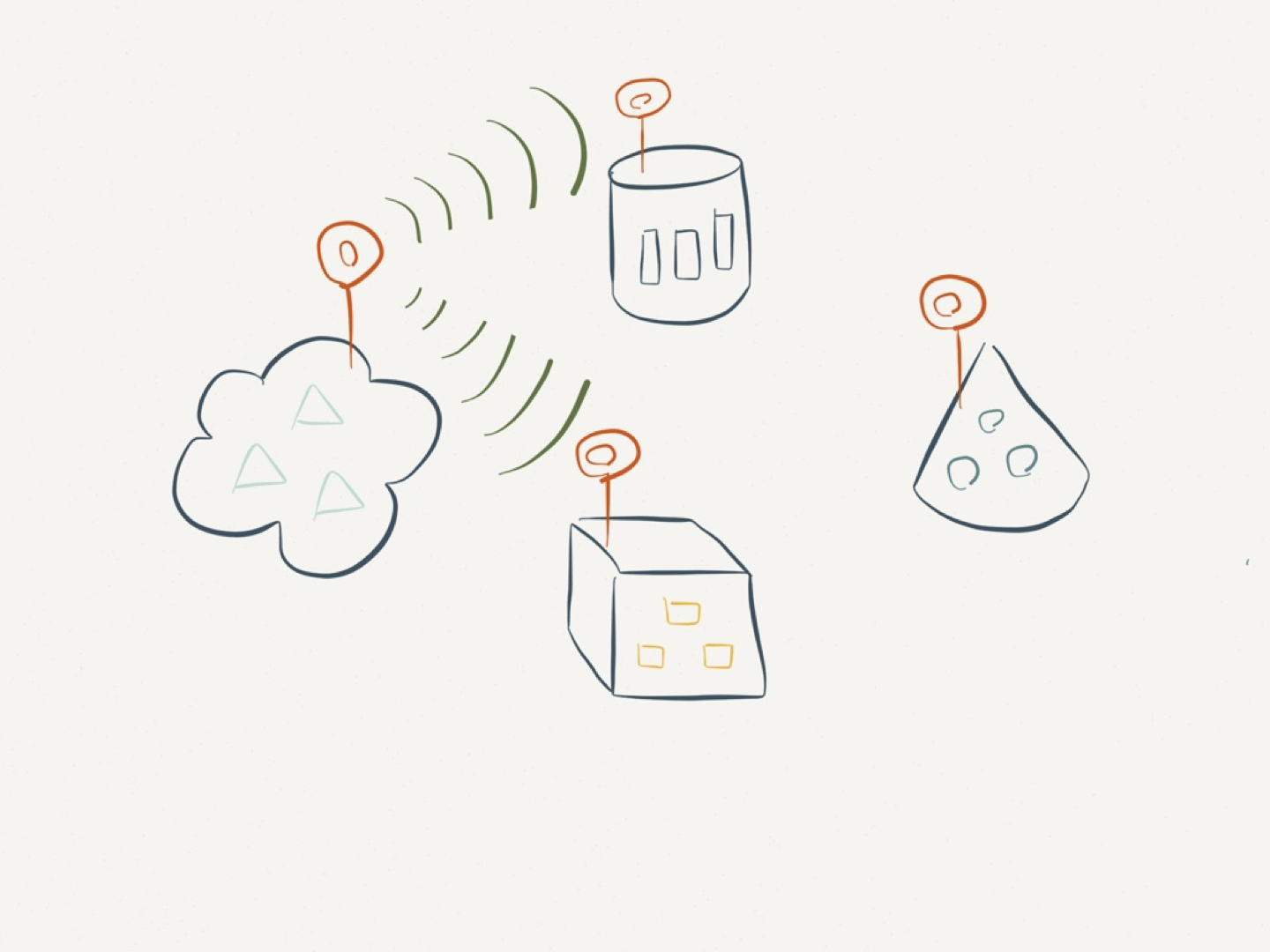
Sources need a notification system through which changes can be observed. Changes in one source must be able to trigger changes in other sources.
Flow control
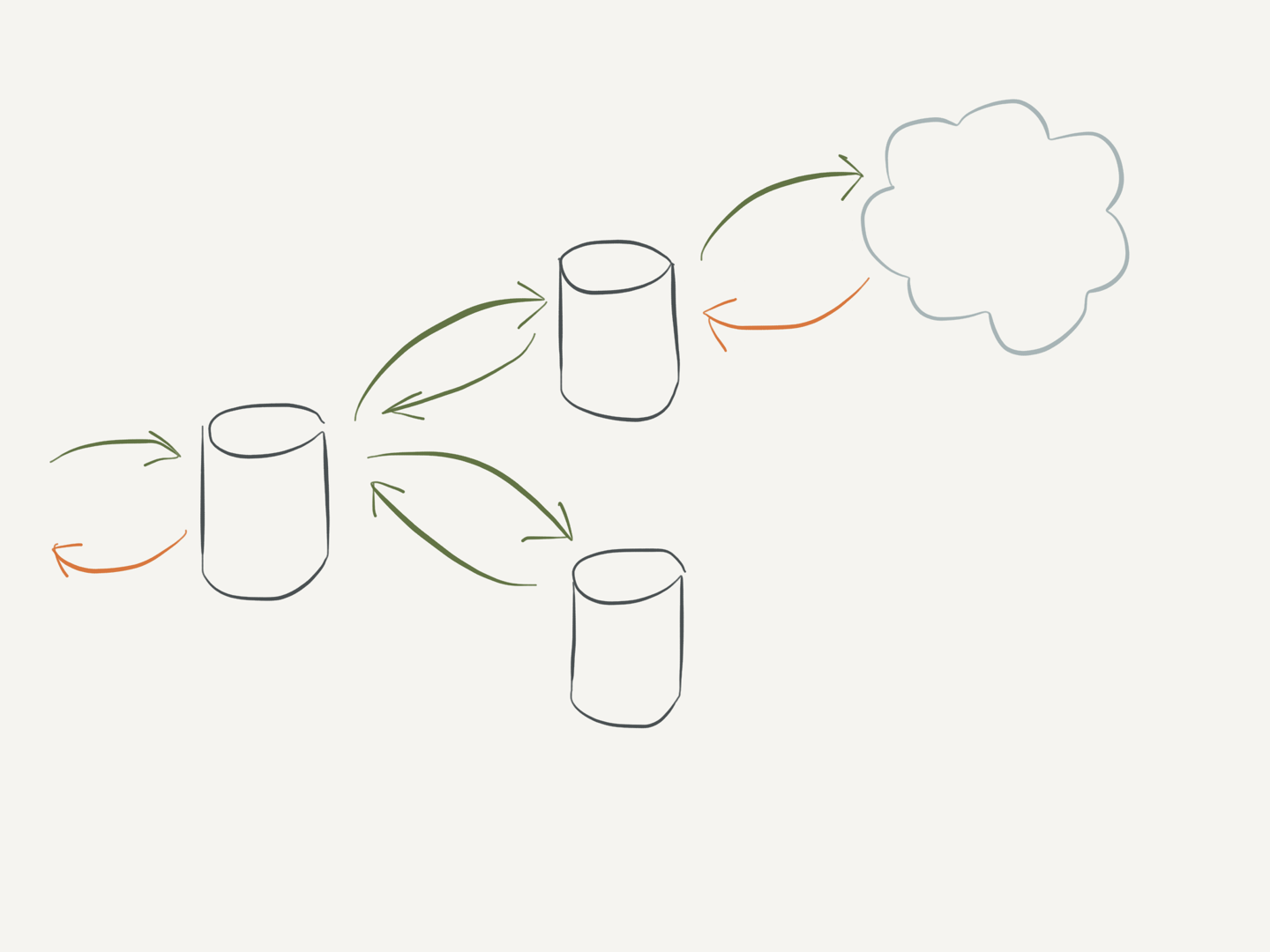
Data flow across sources must be configurable. Flows can be optimistic (successful regardless of their impact) or pessimistic (blocked until dependent changes have resolved).
Change tracking
Mutations, and not just the effects of mutations, must be trackable to allow changes to be logged, diff'd, sync’d, and even reverted.
Orbit primitives
Orbit's core primitives were developed to align with the goals and constraints enumerated above.
Records
Records are used to represent data in a normalized form. Each record has a
type and id, which together establish its identity. Records may also include
other fields, such as attributes and relationships with other records.
Schema
A Schema defines all the models in a given domain. Each Model defines the
characteristics for records of a given type.
Source
Every source of data, from an in-memory store to an IndexedDB database to a REST
server, is represented as a Source. Sources vary widely in their capabilities:
some may support interfaces for updating and/or querying records, while other
sources may simply broadcast changes. Schemas provide sources with an
understanding of the data they manage.
Transform
A Transform is used to represent a set of record mutations, or "operations".
Each Operation represents a single change to a record or relationship (e.g.
adding a record, updating a field, deleting a relationship, etc.). Transforms
must be applied atomically—all operations succeed or fail together.
Query
The contents of sources can be interrogated using a Query. Orbit comes with a
standard set of query expressions for finding records and related records. These
expressions can be paired with refinements (e.g. filters, sort order, etc.). A
query builder is provided to improve the ergonomics of composing queries.
Log
A Log provides a history of transforms applied to each source.
Task
Every action performed upon sources, whether an update request or a query, is
modeled as a Task. Tasks are queued by sources and performed asynchronously
and serially.
Bucket
A Bucket is used to persist application state, such as queued tasks and
change logs.
Coordinator
A Coordinator provides the declarative "wiring" needed to keep an Orbit
application working smoothly. A coordinator observes any number of sources and
applies coordination strategies to keep them in sync, handle problems, perform
logging, and more. Strategies can be customized to observe only certain events
on specific sources.
The Orbit Philosophy
The primitives in Orbit were developed to be as composable and interchangeable as possible. Every source that can be updated understands transforms and operations. Every source that can be queried understands query expressions. Every bucket that can persist state supports the same interfaces.
Orbit's primitives allow you to start simple and add complexity gradually without impacting your working code. Need to support real time sockets or SSE? Add another source and coordination strategy. Need offline support? Add another source and coordination strategy. When offline, you can issue the same queries against your in-memory source as you could against a backend REST server.
Not only does Orbit allow you to incur the cost of complexity gradually, that cost can be contained. New capabilities can often be added through declarative upfront "wiring" rather than imperative handlers spread throughout your codebase.
Although Orbit does not pretend to absorb all the complexity of writing ambitious data-driven applications, it's hoped that Orbit's composable and declarative approach makes it not only attainable but actually enjoyable :)